基于Hadoop的电子产品分析推荐系统设计与实现
随着互联网和电子商务的迅猛发展,电子产品线上销售数据呈现爆炸式增长。如何从海量数据中挖掘用户行为模式,提供精准的个性化推荐,已成为提升用户体验和商业价值的关键。传统的单机推荐算法在处理大规模、高维度的用户-商品交互数据时,面临计算性能瓶颈和扩展性不足的挑战。因此,构建一个基于分布式计算框架Hadoop的电子产品分析推荐系统,不仅契合计算机专业的毕业设计要求,更能为解决实际问题提供高效、可扩展的技术方案。
一、 系统总体设计
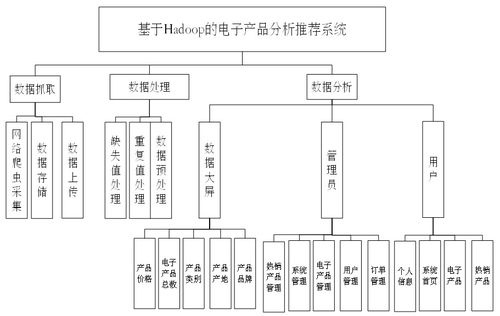
本系统旨在构建一个集数据采集、存储、分析与推荐于一体的综合服务平台。系统架构主要分为三层:
- 数据层:作为系统的基石,负责处理海量异构数据。利用Hadoop生态的核心组件HDFS进行数据的分布式存储,确保高可靠性与高吞吐量。原始数据(如用户浏览日志、购买记录、商品信息、用户画像等)通过Flume或Sqoop等工具进行采集和初步清洗后,存入HDFS。
- 计算与分析层:这是系统的核心,负责从数据中提取价值。我们采用MapReduce编程模型或更高效的Spark计算框架(可部署于YARN资源管理器上)来实现核心的推荐算法。针对电子产品领域的特点,可以融合多种算法:
- 协同过滤:基于用户或物品的相似度进行推荐,能有效挖掘“口碑”效应。
- 基于内容的推荐:分析电子产品的属性(如品牌、型号、价格区间、功能参数),匹配用户的历史偏好。
* 关联规则分析:利用Apriori或FP-Growth算法,发现电子产品间的频繁购买组合(如“购买手机后常购买耳机”)。
该层将原始数据转化为用户偏好模型、商品相似度矩阵、频繁项集等中间结果,并最终生成针对每个用户的个性化推荐列表。
- 应用服务层:面向最终用户或管理员提供交互接口。通过Web服务(如使用Spring Boot框架)封装下层的推荐结果,向用户前端(Web页面或移动App)提供实时或离线的推荐服务。可提供可视化分析仪表盘,展示热门商品、用户群体分析、推荐效果等数据洞察,服务于运营决策。
二、 关键技术与实现要点
- 海量数据处理:Hadoop的分布式文件系统HDFS和分布式计算框架MapReduce/Spark是本项目应对数据规模挑战的核心。需要重点掌握数据分区、Shuffle优化等技术以提升作业效率。
- 推荐算法工程化:将学术上的推荐算法(如矩阵分解、Slope One等)改写成能在集群上并行运行的MapReduce任务或Spark作业是关键难点。需要考虑数据倾斜、迭代计算等问题的解决方案。
- 系统集成与性能优化:系统涉及Hadoop生态多个组件(如HDFS, MapReduce/Spark, Hive用于离线查询,HBase用于快速检索等)的协同工作。需要合理设计数据流,优化集群配置,并进行压力测试以确保系统稳定高效。
- “计算机系统服务”视角的融入:在设计与实现中,应充分体现系统服务的特性。这包括:
- 高可用性与容错性:利用Hadoop自身的数据多副本机制和任务重试机制保障服务不间断。
- 可扩展性:系统设计应支持通过增加集群节点线性扩展存储和计算能力。
- 服务质量:考虑推荐服务的响应时间、准确性(通过A/B测试评估)和覆盖率等指标。
- 维护与管理:设计相应的日志监控、故障报警和资源调度策略。
三、 开发实践与评估
在具体开发中,可以选取公开的电商数据集(如Amazon Product Data)或模拟生成数据进行原型开发。开发流程包括环境搭建(Hadoop伪分布式或完全分布式集群)、算法实现与调试、前后端集成、系统测试等环节。
对系统的评估应兼顾技术指标和业务指标:技术指标包括作业执行时间、集群资源利用率;业务指标则包括推荐准确率、召回率、F1值以及在线测试的用户点击率、转化率等。
结论
设计并实现一个基于Hadoop的电子产品分析推荐系统,是一项极具挑战性和实用价值的计算机毕业设计课题。它不仅要求学生综合运用大数据技术、机器学习算法和软件开发技能,更要求从“系统服务”的高度思考架构的可靠性、扩展性与可用性。通过本项目,学生能够深入理解分布式计算原理,掌握大数据分析与推荐系统的核心构建流程,为未来从事大数据、人工智能等相关领域的工作奠定坚实的实践基础。该系统模型亦可扩展至图书、电影等其他垂直电商或内容推荐领域,具备良好的普适性。
如若转载,请注明出处:http://www.saic-ai-lab.com/product/53.html
更新时间:2026-06-19 04:14:46